

Data Acquisition's Journey to the Cloud
LC
Leo Cao • July 19, 2025
Leo Cao • July 19, 2025
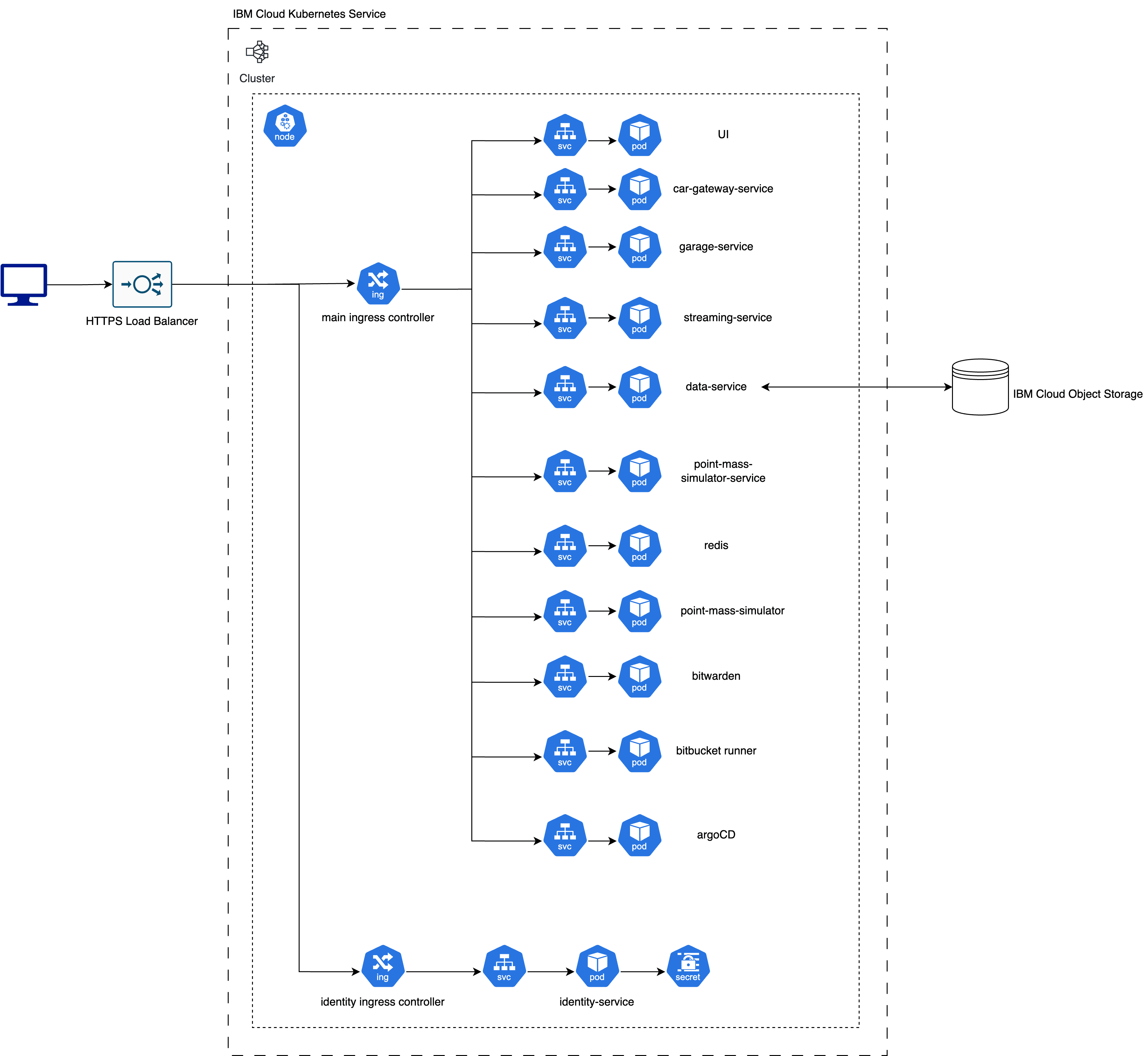
Figure 1. 2022 Cloud Architecture
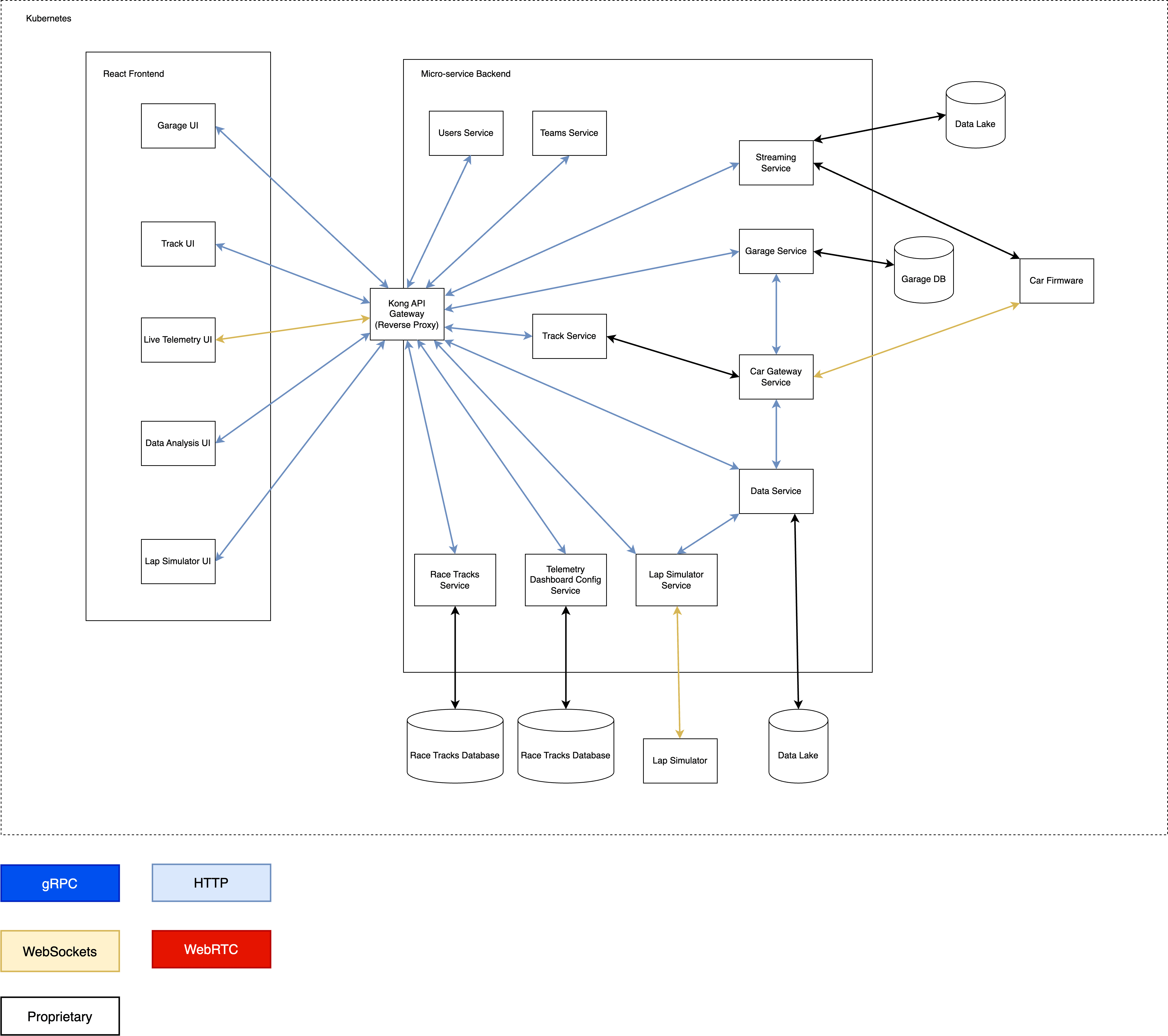
Figure 2. Container Diagram of 2022’s Cloud Architecture
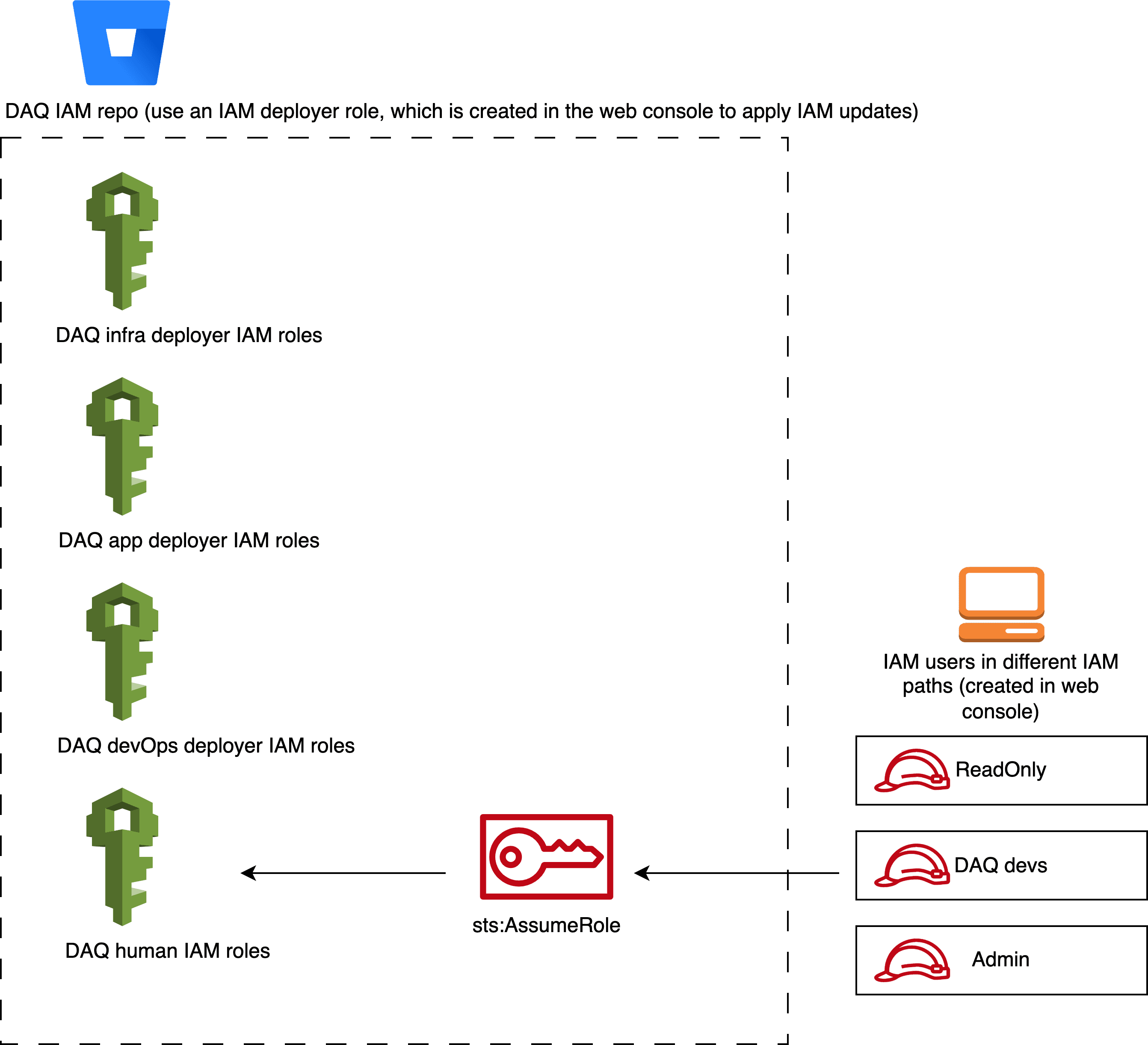
Figure 3. DAQ IAM design
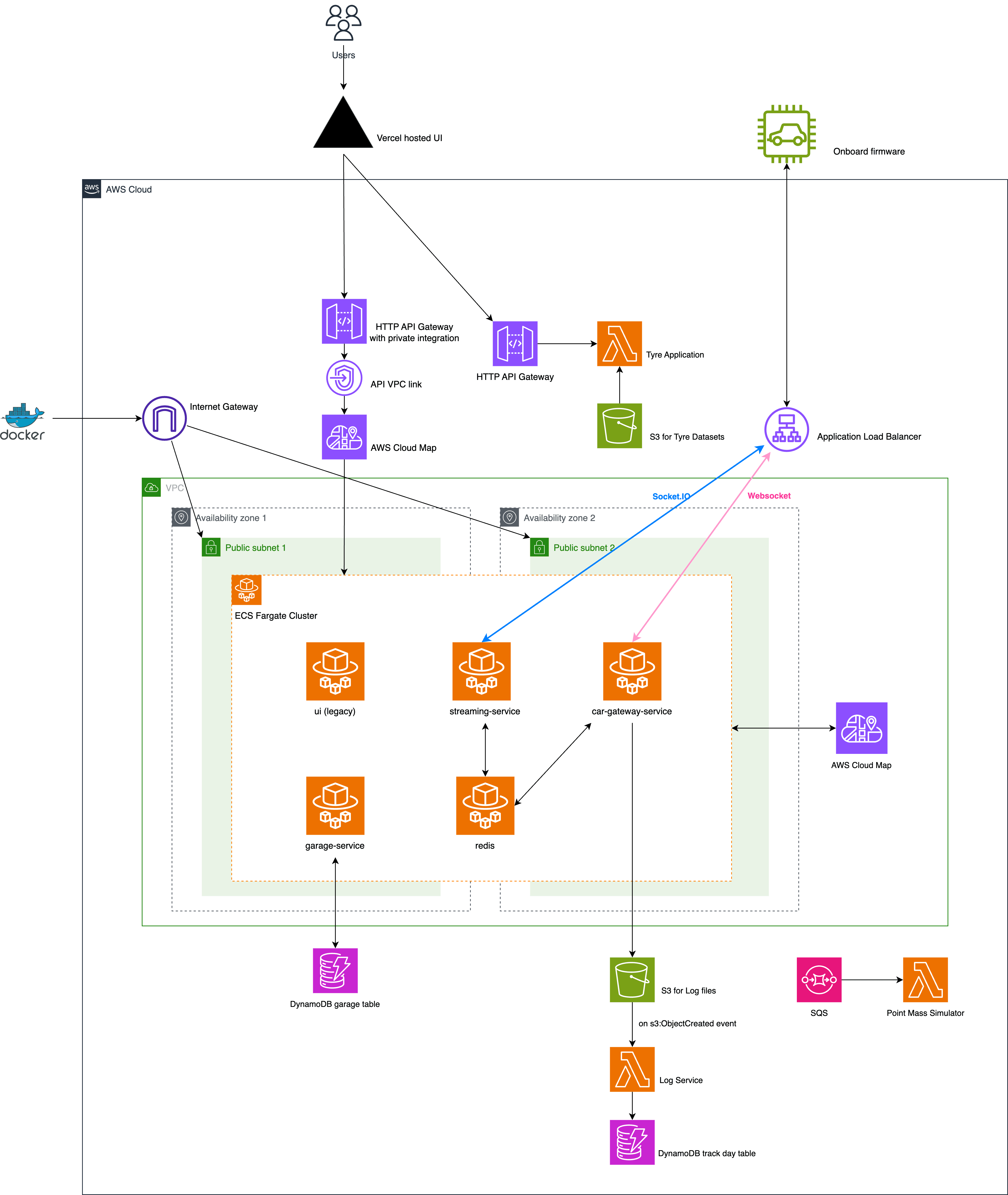
Figure 4. DAQ AWS Architecture (October 2023)
Figure 5. The 2023 Redback Racing Team at Competition
Data Acquisition (DAQ)’s Journey to the Cloud has evolved from its department’s creation in 2020 to the infrastructure and paradigm that Redback benefits from today. The team depends on real-time data from various components to analyse performance, allowing the teams to make informed decisions on areas of prioritization and improvement. Redback Racing’s 2022 Data Acquisition Lead Leo Cao shares below the department’s journey to deploy the team’s custom software to the cloud.
Redback Racing reached a sponsorship with a cloud provider in 2021 and Data Acquisition (DAQ) designed and deployed our telemetry system onto Kubernetes Service by the end of 2021. A detailed blog is here. DAQ’s applications were all largely deployed into one Kubernetes node. A load balancer together with an ingress controller were configured to distribute and handle network traffic.
Figure 1 displays what the DAQ systems looked like in terms of Kubernetes at the end of 2022.
Figure 2 is another view of the more detailed system architecture:
You can see this was a straight forward design. We only used a single worker node and we hadn’t even started to up-scale it. I like the Kubernetes design because it is extremely easy to manage a large set of applications because each of them is deployed into a Kubernetes pod and you get service discovery inside a worker node for free. They have the exact same deployment procedure and this greatly benefits us in terms of streamlining our backend micro-services' Continuous Integration/Continuous Deployment (CI/CD) overhead and improves efficiency. This is a good example of "undifferentiated heavy lifting" where you have a group of experts managing infrastructure, providing necessary abstractions, standardisation and automation, which frees the team’s other developers to work on core product features that users can’t get anywhere else.
We had a centralised repository called infrastructure which stored all configurations and handled deployment to the Kubernetes cluster written in Terraform. A repository called deployments, which had manifests for applications we built and things we self-hosted such as the Bitbucket pipeline and Bitwarden, were synced with ArgoCD. Internally for each application repository, we had one CD step which was triggered at the end of a pipeline to automatically create a pull request in deployments repository for deployment. Relevant people including the author of the original pull request (PR) and the cloud operation engineers would get tagged as reviewers. After the deployment PR was merged, ArgoCD synced the head of the main branch and deployed to Kubernetes.
After the sponsorship started, we were allocated a cloud credit budget, but there was no guidance on how to approach architecting a scalable software system in the cloud. Fortunately, a few talented students in DAQ managed to implement a working solution using the cloud provider’s Kubernetes Service. Our Telemetry System had been running on the cloud since the end of 2021.
One of our core services is the streaming service. Its primary responsibility is to live stream car metadata and store them in Redis. To allow both our streaming service and Redis instance to run on the cloud reliably for prolonged periods of time, we required significant amounts of compute. Limited by our budget, our streaming service often crashed or hung during intensive runtime scenarios. Additionally, the contract with our cloud provider was going to expire in May 2023, so we immediately needed to think about either trying to renew with them (and ask for a higher budget) or look for alternative options. Around the end of 2022, we started to seek alternatives, one being Amazon Web Service (AWS).
While discussing the partnership with AWS, DAQ had internal discussions about the approach of migrating from the previous cloud provider to AWS. One obvious solution is to stick with Kubernetes. Kubernetes itself is platform-agnostic and there should be minimal vendor lock-in using it. Lift-and-shifting applications from a managed Kubernetes service to AWS Elastic Kubernetes Service (EKS) should be easy. Our Kubernetes architecture will remain pretty much the same and the migration process should be quick. The other opinion was that this might be a good opportunity to refactor and adopt a “serverless” architecture.. We thought that if we could adopt this model, leveraging AWS Lambda functions, Fargate Elastic Container Service (ECS) or other serverless offerings, we could achieve "scale to zero", which greatly reduces cost. The ideal scenario is that our Telemetry System is able to scale up only when we are using them, whereas in a Kubernetes world everything is running 24/7 by default. In addition, the maintenance overhead for Kubernetes had started to take a toll on us in 2022 with key members leaving the team. In September 2022, I broke the entire Kubernetes cluster because of a version upgrade and ended up spending two weeks trying to bring everything back up. This experience highlighted the complexity of maintaining Kubernetes clusters and the need for specialised expertise to ensure smooth operation. Unfortunately, opportunities to work hands-on with Kubernetes at this scale are rare in university settings, leaving many students unprepared for such challenges. AWS Serverless services, on the other hand, eliminate this concern because the underlying infrastructure maintenance is covered by AWS. At the time, I thought this was also a good opportunity to learn about various AWS services such as ECS, lambda functions etc. instead of sticking to Kubernetes. Therefore, we eventually made the call to go with the serverless option.
I won't go into every detail of the migration, but there are several components that I think are worth mentioning. They are the AWS Identity and Access Management (IAM) setup and the use of AWS Application Load Balancer (ALB) vs API Gateway V2.
One important aspect of getting started with AWS is setting up IAM correctly, as it controls which roles can access specific resources and actions using policies. I was personally working on an IAM task in a company of 100+ developers at the time so I thought we could use that as an example and adopt some of their methodologies.
The IAM setup for the human role access is to have two layers of IAM. The top IAM layer connects to the Identity Provider (IdP) so when the user tries to log into the company’s AWS web console with Single Sign-On (SSO), the page is directed to the IdP. In Entra (the IdP used by the company at that time), each employee belongs to different user groups such as “ReadOnly“, “Developer“, “Admin“, etc. The top IAM layer uses those group names as the IAM names and this layer has zero permission to access anything inside AWS. The second (bottom) layer of IAM defines the actual IAM policies to different services and resources such as s3:List*, s3:Get* and s3:PutObject actions. The bottom layer connects to the top layer by using assume_role_policy. It is a special policy associated with a role that controls which principals (users, other roles, AWS services, etc) can "assume" the role. Assuming a role means generating temporary credentials to act with the privileges granted by the access policies associated with that role. As a result, the employee logs into the AWS web console with zero access and then clicks the switch role button to assume a specific role to perform actions on specific AWS resources. It is also important to not have any bottom layer role being assumed by any user. To prevent this, in each role of the second IAM layer, there is an aws_iam_policy_document that defines the principals.identifiers which targets the corresponding top layer IAM roles.
No human IAM role has been given the action to create resources or services because provisioning is done by Infrastructure as Code (IaC) tools. Therefore, another set of IAMs are created by using IaC just for CI/CD. Those IAM roles are defined based on either the department, project team, product, or different parts of the system.
Relevant information on this decision: AWS Identity and Access Management (IAM) Best Practices - Amazon Web Services
Each DAQ <your_type> IAM role in this IAM repository is a Terraform module which uses a custom module. The top three will be used for the pipelines to assume. These are rough definitions of how we will delegate roles to our apps and infrastructure. The last DAQ human IAM roles module is used for human users to assume as seen in Figure 3.
One of the initial milestones of the migration was to move everything across to AWS Elastic Container Service (ECS) and one immediate realisation was there was no service discovery between ECS containers whereas it is built in for Kubernetes. Fortunately, AWS Cloud Map solved this problem.
While setting up the Application Load Balancer for each service, I found the process to be extremely complicated and error-prone. Case in point, you need aws_lb_target_group, aws_lb_listener_rule for each ECS service and a aws_lb_listener to distribute the traffic. The configurations ended up scattered across different Terraform files and it was also difficult to get a holistic view of the ingress rules in the AWS web console. As a result, I could never achieve the simplicity of something like an ingress controller in Kubernetes which uses only one YAML file to describe reverse proxy rules. Even if I could somehow tolerate this complicated setup, ALB was not a sustainable choice for DAQ because of the cost. The load balancer by itself is at least $18/month and the whole point of using lambdas and ECS is to achieve "scale to zero".
I found a nice solution where we could forego ALB entirely - and still get TLS termination and balancing load over multiple containers. You just need to use API Gateway HTTP API’s support for private integrations.
Instead of $18+ per month, it is billed by the invocations and it is $1.29 for the first 300 million per month. For the traffic that Telemetry System receives, this is a huge saving. The configuration is also simpler. API Gateway V2 works nicely with Lambda functions and other AWS serverless offerings so this is also a huge benefit.
The final architecture looks like this (October 2023 version) as shown in Figure 4.
In September 2023, we successfully live-streamed on AWS, confirming that the migration was complete.
During the 2023 Formula SAE-A competition, the telemetry system played an important role in the endurance event and we won 2nd overall and 1st in Australia.
AWS wrote a blog about this achievement
UNSW students build an all-electric race car with AWS | Amazon Web Services.
The ultimate goal of migrating to AWS in 2023 is to achieve a stable, performant and extensible cloud infrastructure foundation so that future DAQ teams can continuously iterate and build on top of it. I am looking forward to the future of Redback Racing and I have no doubt that DAQ will keep helping the rest of the team to achieve new heights in FSAE.
It is clear that the journey through the cloud from 2021 to 2023, is a clear example of how students, given the resources, are able to achieve meaningful outcomes and progress. As Redback Racing, exploring and implementing new systems to further enhance the team’s capabilities, including advancing Redback’s autonomous systems technology, will bridge the gap between young engineers, industries, and the technology they interface with.